Abstract
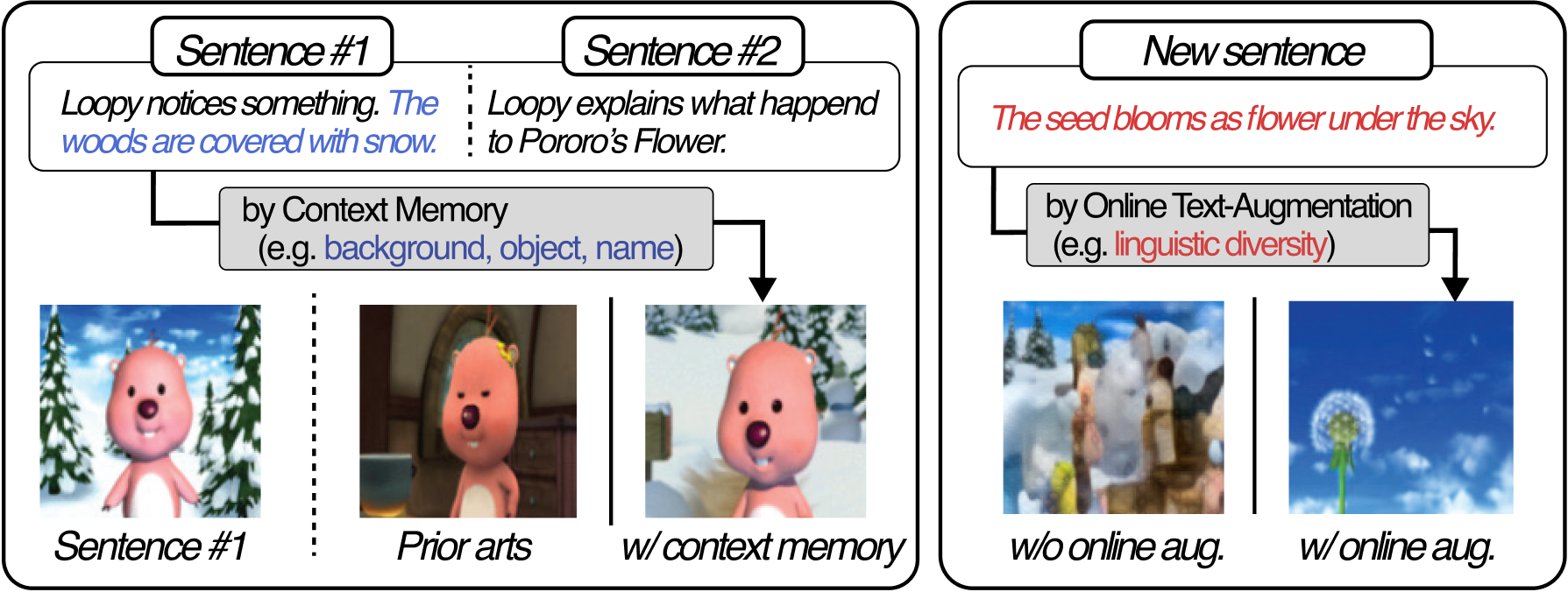
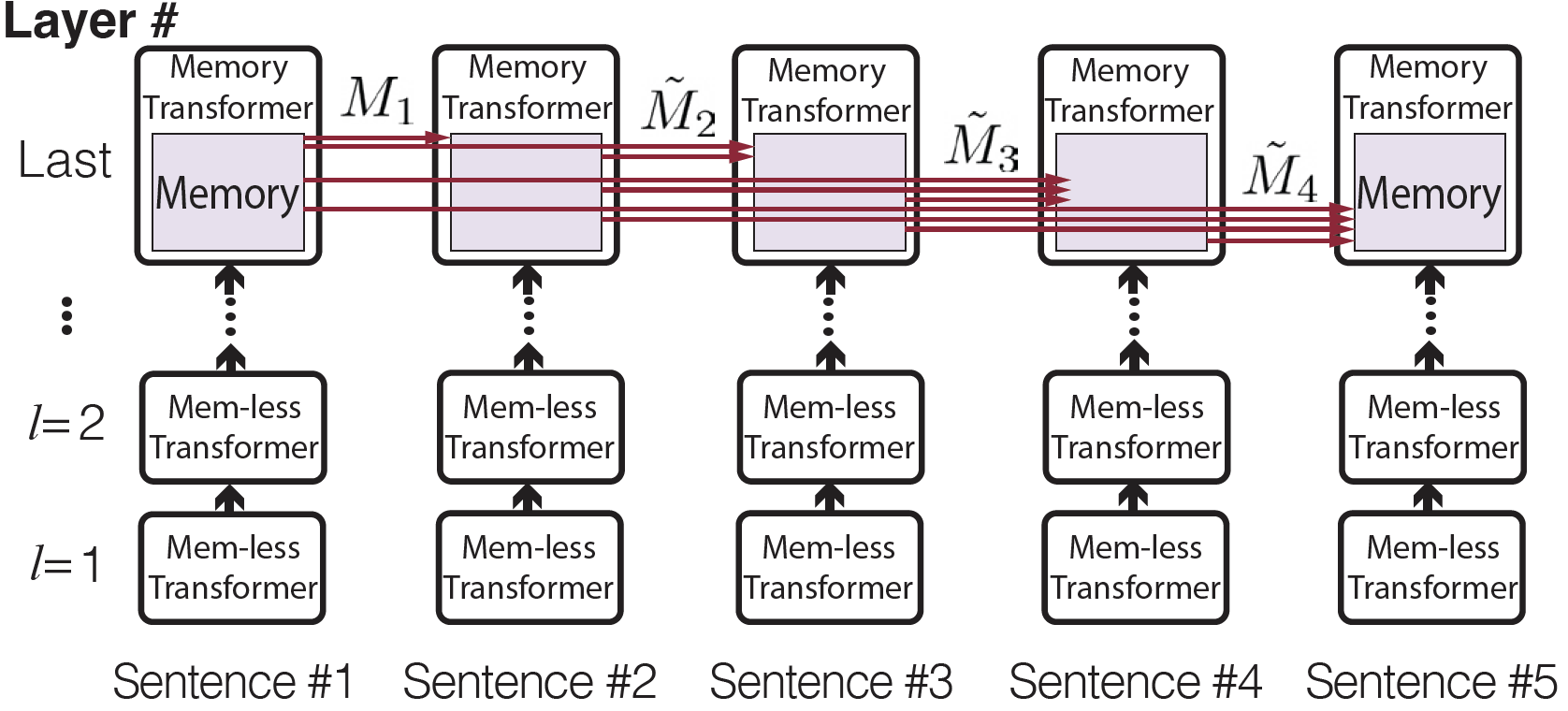
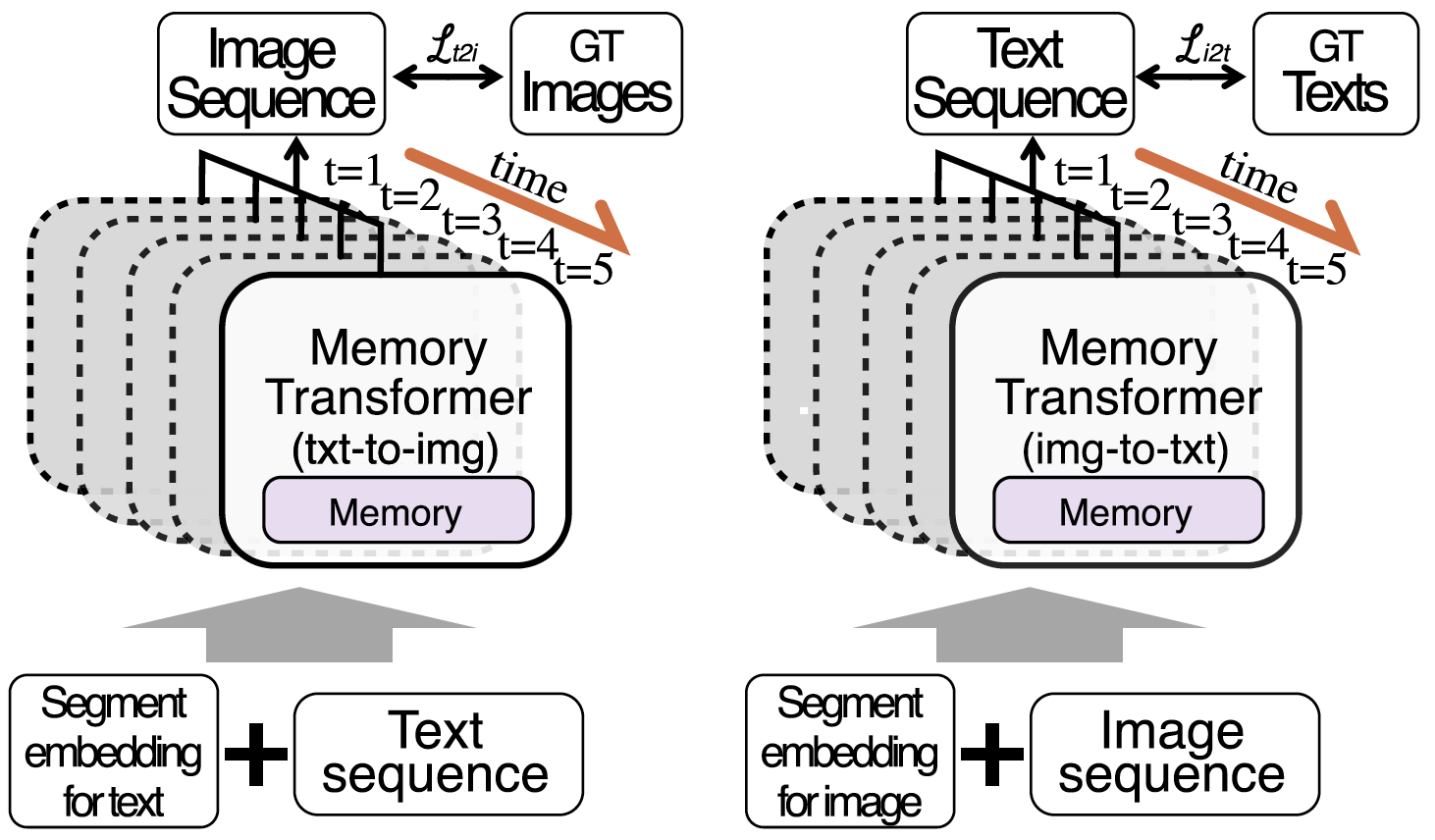
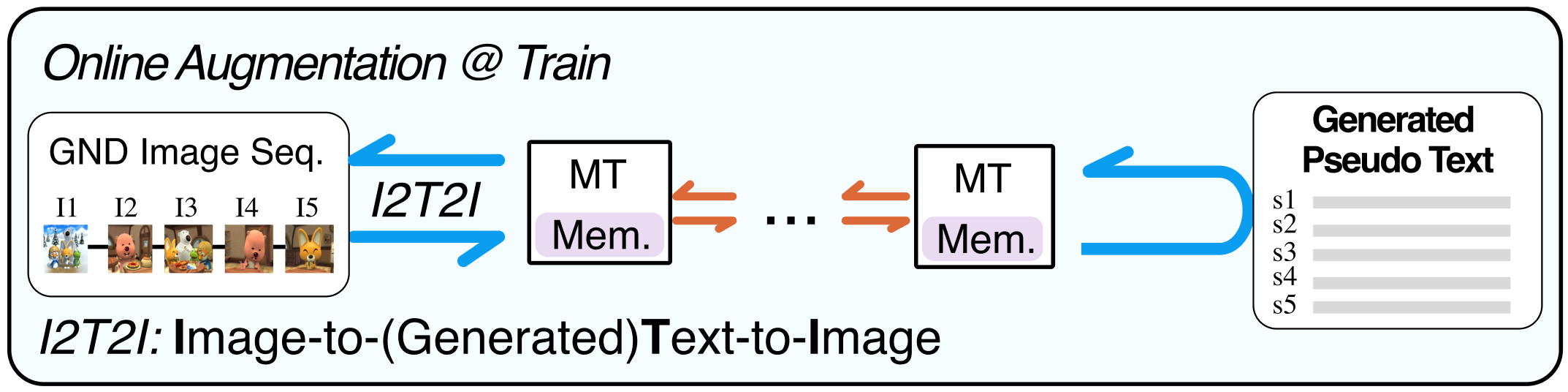
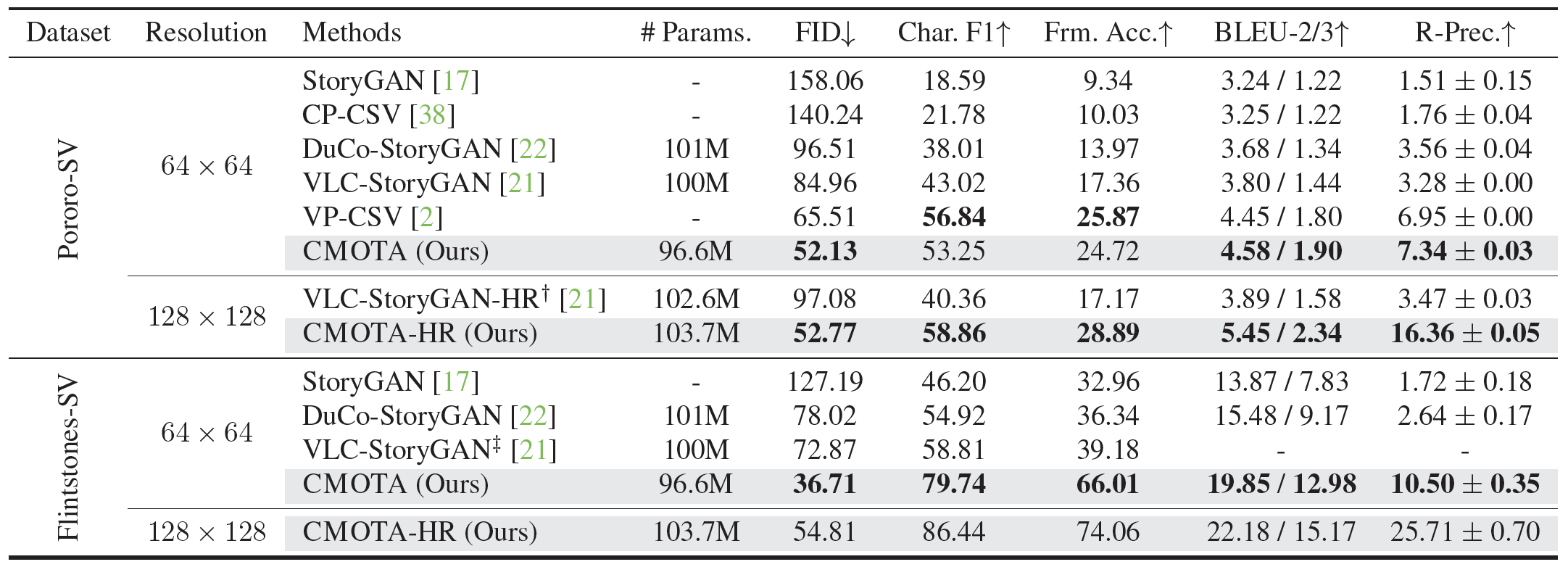
Story visualization (SV) is a challenging text-to-image generation task for the difficulty of not only rendering visual details from the text descriptions but also encoding a long-term context across multiple sentences. While prior efforts mostly focus on generating a semantically relevant image for each sentence, encoding a context spread across the given paragraph to generate contextually convincing images (e.g., with a correct character or with a proper background of the scene) remains a challenge. To this end, we propose a novel memory architecture for the Bi-directional Transformers with an online text augmentation that generates multiple pseudo-descriptions as supplementary supervision during training, for better generalization to the language variation at inference. We call our model as Context Memory and Online Text Augmentation or CMOTA for short. In extensive experiments on the two popular SV benchmarks, i.e., the Pororo-SV and Flintstones-SV, the proposed method significantly outperforms the state of the arts in various evaluation metrics including FID, character F1, frame accuracy, BLEU-2/3, and R-precision with similar or less computational complexity.