
I'm a Ph.D. student at SNU Machine Perception and Reasoning Lab. at Seoul National University advised by Prof. Jonghyun Choi.
My research focuses on building AI agent that perceive, reason, and act as humans do, progressing from video-language understanding and multimodal alignment to agent reasoning and real-world robotic manipulation. See my research statement for details.
CV / Research Statement / LinkedIn / Github / Google Scholar / Email
- 2026.05: SCALE is accepted to CVPR ActiVis Workshop! 🇺🇸
- 2026.05: SCALE is accepted to ICML 2026 as Spotlight presentation! 🇰🇷
- 2026.04: LWE is accepted to ACL EvalEval Workshop as Oral presentation! (Extension of EACL) 🇺🇸
- 2026.04: Summarize my research so far in a research statement!
- 2026.01: BINDER is accepted to ICRA 2026! 🇦🇹
- 2026.01: LWE is accepted to EACL 2026 as Oral presentation! 🇲🇦
- 2025.11: VECTOR is accepted to WACV 2026! 🇺🇸
- 2025.07: HIMA is accepted to COLM 2025! 🇨🇦
- 2025.06: Selected as Outstanding Reviewer at CVPR 2025 (Top 5.6%)
- 2025.02: MA-VR is published in IEEE ACCESS 2025!
- 2024.12: ISR-DPO is accepted to AAAI 2025! 🇺🇸
- 2024.05: VLM-RLAIF is accepted to ACL 2024 as Oral presentation! 🇹🇭
- 2023.07: CMOTA is accepted to ICCV 2023! 🇫🇷
- 2022.10: Received Best Paper Award at the 1st Yonsei AI Workshop
- 2021.07: PSVL is accepted to ICCV 2021 as Oral presentation! 🌐
|
* denotes equal contribution | [C] Conference, [J] Journal, [P] Preprint |
Preprints
|
San Kim* , Daechul Ahn* , Reokyoung Kim , Hyeonbeom Choi , Seungyeon Jwa , Jonghyun Choi arXiv, 2026 [paper (arXiv)] [bibtex] [project] tl;dr: We introduce RTSGameBench, a large-scale RTS benchmark for evaluating VLMs’ strategic reasoning through diverse full-game matchups, diagnostic mini-games, and a self-evolving game generation framework. |

Publications in Multimodal, Agentic, and Embodied AI
|
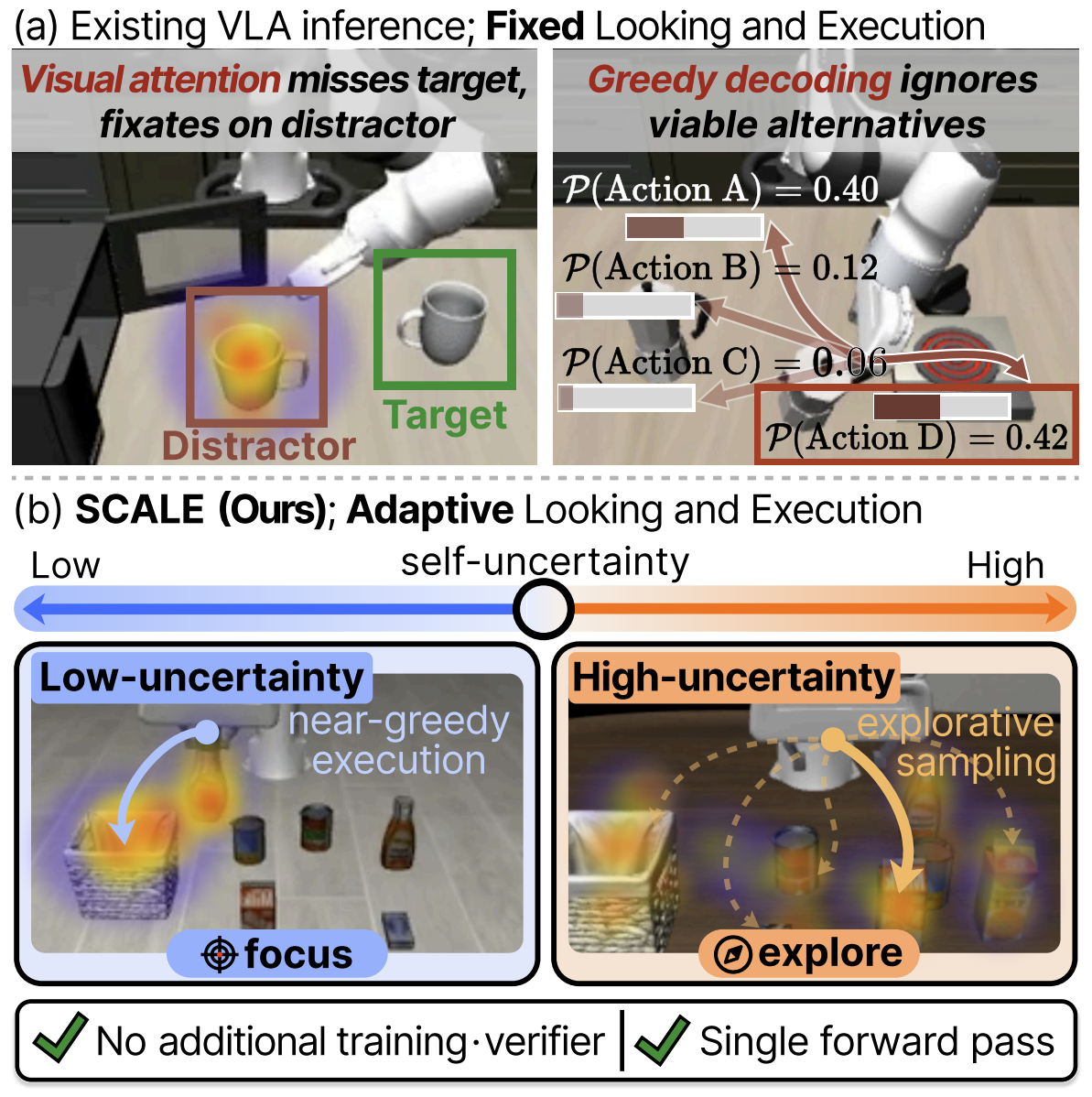
Hyeonbeom Choi* , Daechul Ahn* , Youhan Lee , Taewook Kang , Seongwon Cho , Jonghyun Choi ICML 2026 (Spotlight presentation) / CVPR ActiVis Workshop 2026 [paper (arXiv)] [bibtex] [code] [project] tl;dr: We tackle test-time robustness of VLA models without additional training or multiple forward passes, by proposing SCALE: jointly modulate visual attention and action decoding based on self-uncertainty. |
|
|
Seongwon Cho* , Daechul Ahn* , Donghyun Shin , Hyeonbeom Choi , San Kim , Jonghyun Choi ICRA 2026 [paper (arXiv)] [bibtex] [code] [project] tl;dr: We tackle open-vocabulary mobile manipulation in changing scenes, by proposing BINDER: separate deliberative planning from continuous video monitoring to update state and trigger replanning. |
|
|
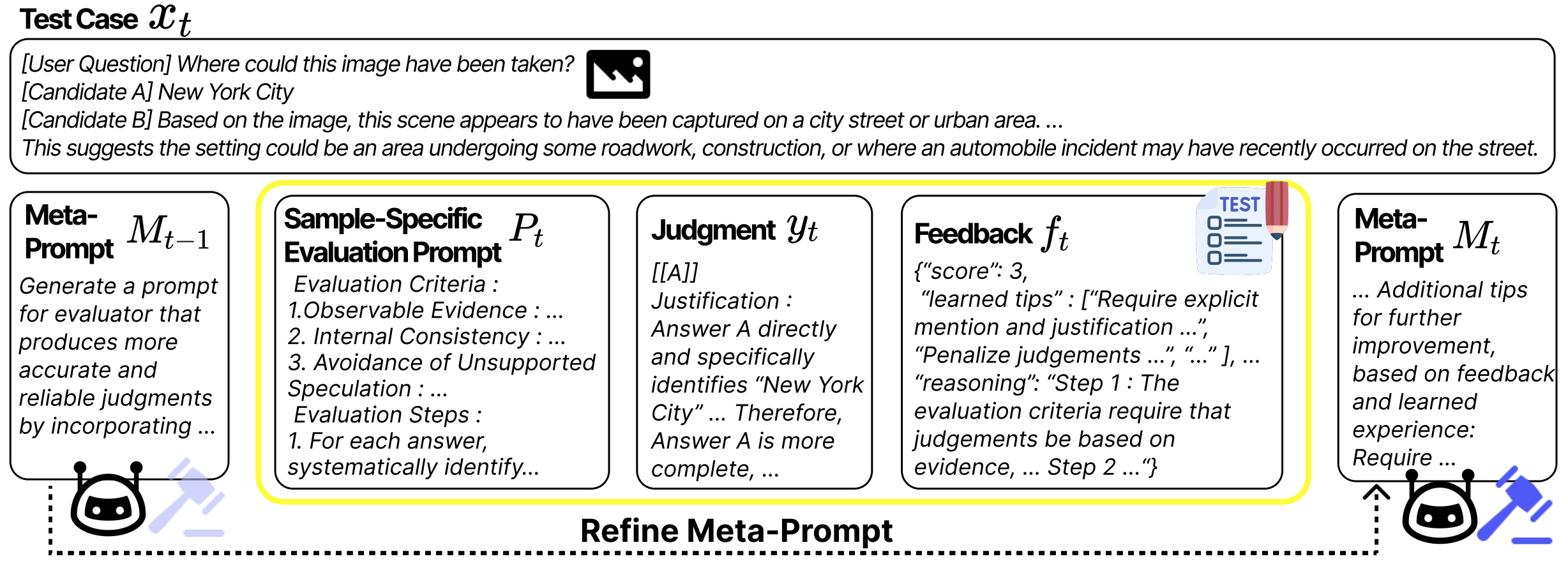
Seungyeon Jwa , Daechul Ahn , Reokyoung Kim , Dongyeop Kang , Jonghyun Choi EACL 2026 (short) (Oral presentation) / ACL EvalEval Workshop 2026 (long) (Oral presentation) [paper] [paper (extended version)] [bibtex] [code] tl;dr: We tackle brittle VLM-as-a-judge evaluation, by proposing Learning While Evaluating: an evolving meta-prompt that self-improves at test time, updated selectively on inconsistent cases. |
|
|
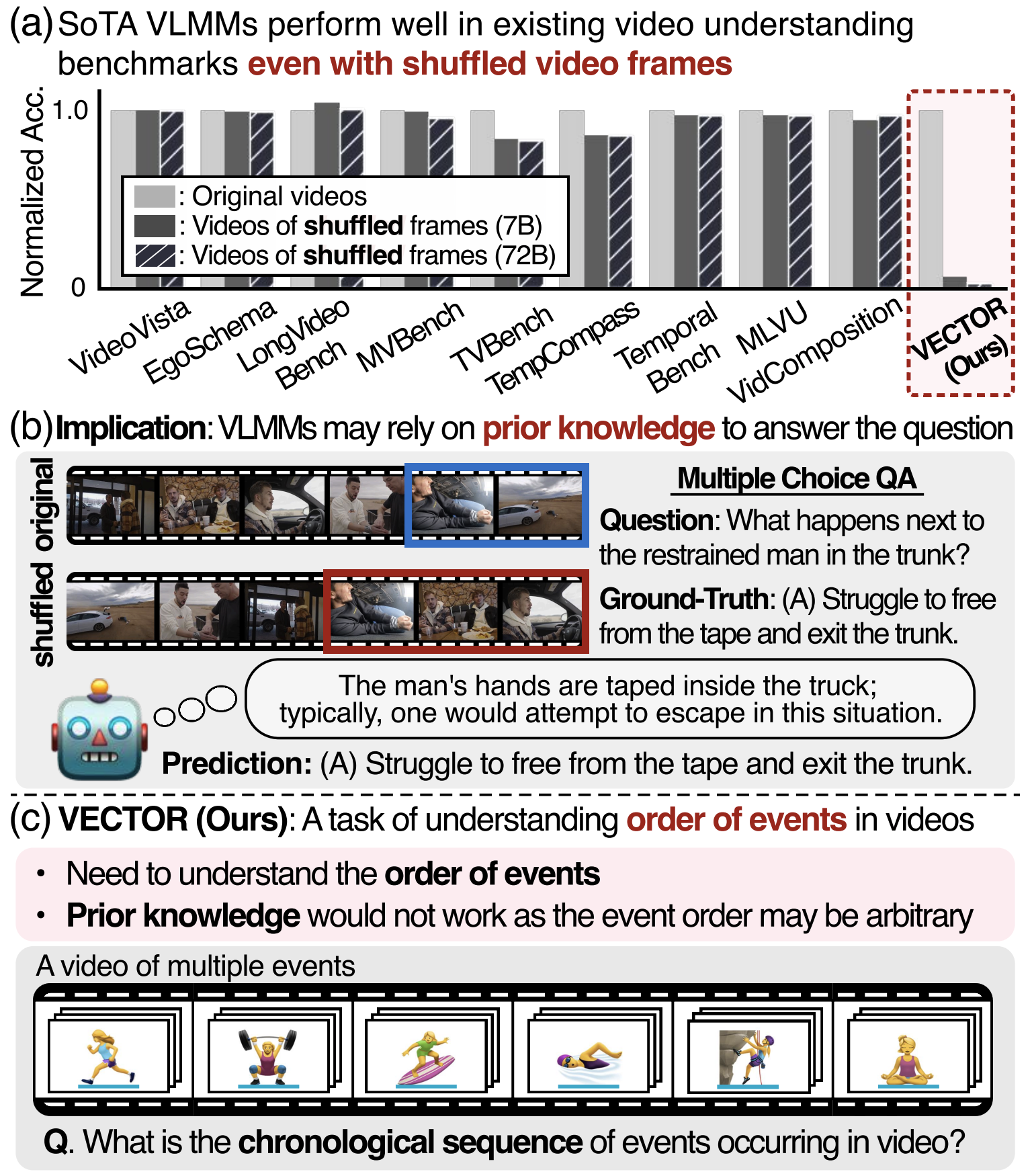
Daechul Ahn* , Yura Choi* , Hyeonbeom Choi* , Seongwon Cho , San Kim , Jonghyun Choi WACV 2026 [paper (arXiv)] [bibtex] [code] [project] tl;dr: We tackle weak temporal-order understanding in video models, by proposing VECTOR (a temporal-order diagnostic) and MECOT (event-by-event instruction + CoT) to teach explicit ordering. |
|
|
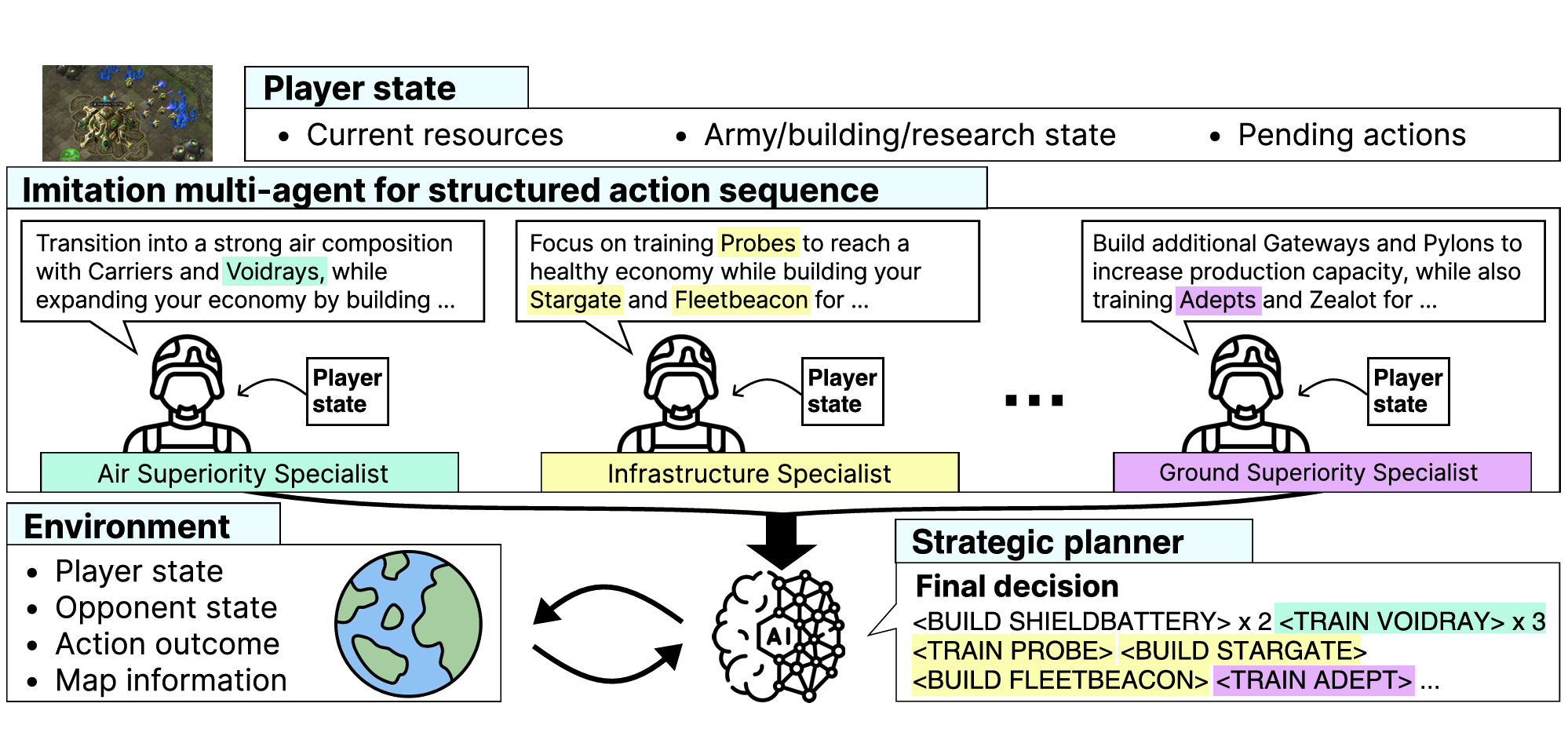
Daechul Ahn* , San Kim* , Jonghyun Choi COLM 2025 [paper] [arXiv] [bibtex] [code] [project] tl;dr: We tackle long-horizon strategy in real-time games, by proposing a hierarchical multi-agent system where specialist agents propose plans and a meta-planner composes them. |
|
|
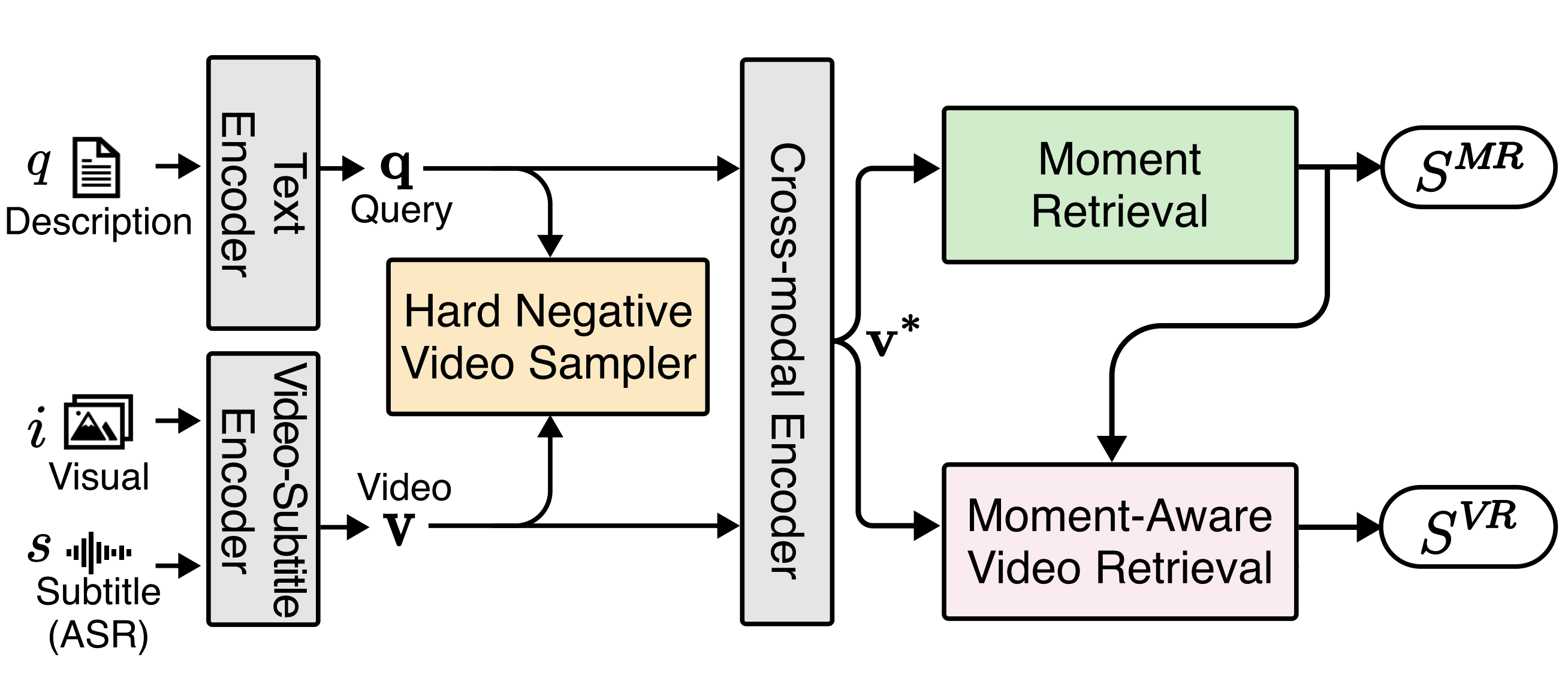
Yura Choi* , Daechul Ahn* , Jonghyun Choi IEEE ACCESS 2025 [paper] [bibtex] tl;dr: We tackle suboptimal decomposed VCMR learning, by proposing moment-aware video retrieval that ties video retrieval to predicted moments and curriculum hard-negative mining. |
|
|
Daechul Ahn* , Yura Choi* , San Kim , Youngjae Yu , Dongyeop Kang , Jonghyun Choi AAAI 2025 [paper] [arXiv] [bibtex] [code] [project] tl;dr: We address preference optimization drift in video LMMs, by proposing self-retrospective DPO that repeatedly re-checks visual evidence to reduce language-only shortcuts. |
|
|
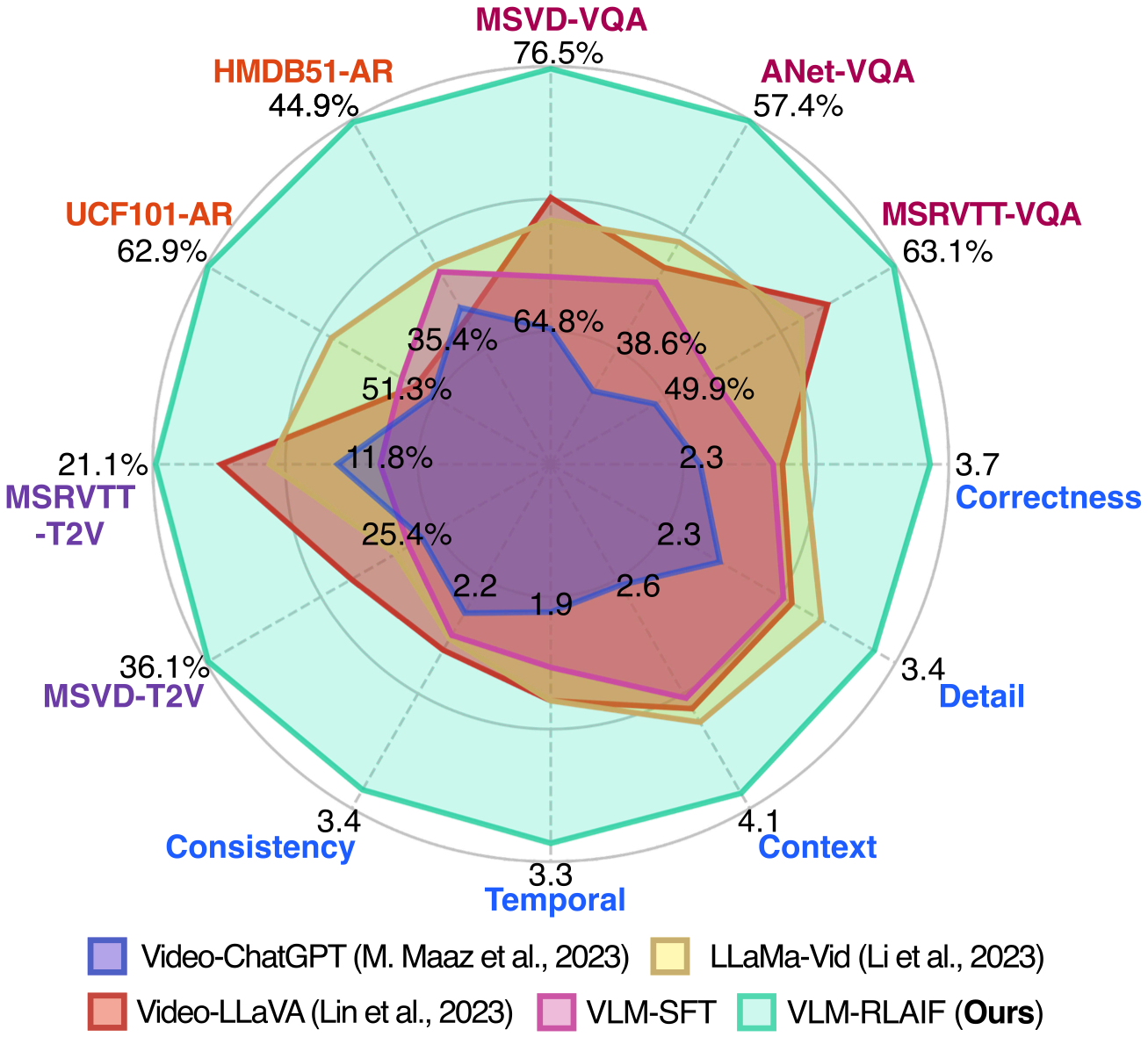
Daechul Ahn , Yura Choi , Youngjae Yu , Dongyeop Kang , Jonghyun Choi ACL 2024 (Oral presentation) [paper] [bibtex] [code] [project] [demo] tl;dr: We tackle video–language model alignment with limited human feedback, by proposing RLAIF with a context-aware reward that makes AI-generated preferences more video-grounded. |
|
|
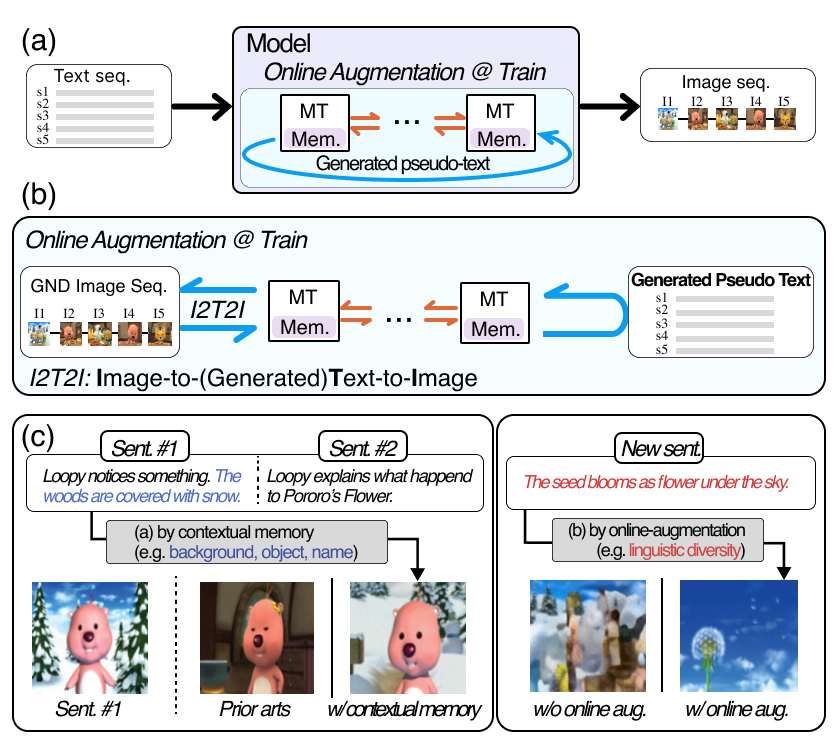
Daechul Ahn , Daneul Kim , Gwangmo Song , Seung Hwan Kim , Honglak Lee , Dongyeop Kang , Jonghyun Choi ICCV 2023 [paper] [bibtex] [code] [project] tl;dr: We address long-range consistency in story visualization, by proposing a Transformer with context memory plus online text augmentation for robust, coherent generation. |
|
|
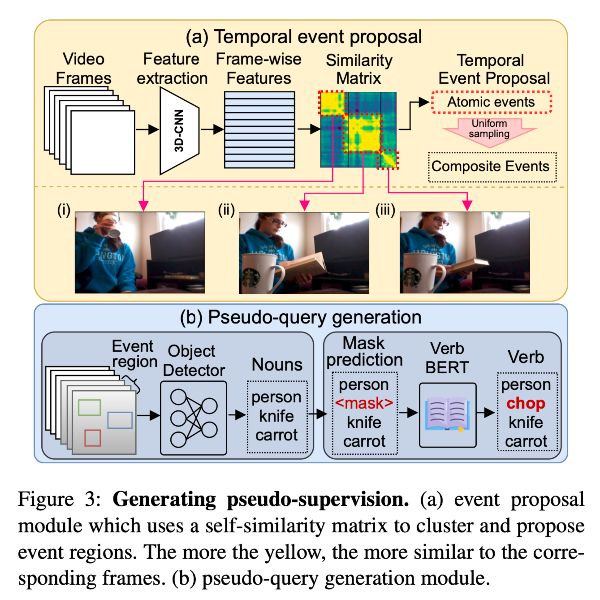
Jinwoo Nam* , Daechul Ahn* , Dongyeop Kang , Seong Jong Ha , Jonghyun Choi ICCV 2021 (Oral presentation) [paper] [bibtex] [code] tl;dr: We tackle video moment localization without paired labels, by proposing pseudo-supervision that converts unpaired text and unlabeled videos into synthetic query–segment training pairs. |


Past Research: Semiconductor [Show details]
Research conducted at KAIST during M.S. (2015–2017).
-
Recognized as a ICML 2026 Silver Reviewer
-
Recognized as a CVPR 2025 Outstanding Reviewer
-
Computer vision Best Paper Award at the 1st Yonsei AI Workshop @ Oct 2022
Reviewer (conference and journal)
- CVPR, ICCV, ECCV, ICML, NeurIPS, COLM, AAAI, WACV, ICRA, IJCV, TPAMI, Pattern Recognition
- In my free time, I usually enjoy playing volleyball 🏐 and taking photographs 📸 (dafoto.info) as a hobby.
|
This template is from Jon Barron. |